


There’s been a lot of chat about synthetic sample. Is it going to take over from human panellists? Or act as a booster to panel responses? Most importantly, is the data generated of sufficiently high quality? Or is it all just hype?
First of all, let’s understand what synthetic sample is. It’s the ability to use generative AI or more generally predictive modelling to literally generate human-style responses to questions, based on the datasets available. Instead of survey responses, asking a real human panellist, generative AI (LLMs like GPT-4) or predictive models can be used as proxies for human responses from surveys.
Hypothetically, there could be some advantages for market research – reducing the interview length being a key one, perhaps using human panellists for key questions and supplementing with synthetic sample for more generic attitudes or additional data requirements to add flavour.
But high-quality data is something that all brands require. For the first time, Kantar is releasing exclusive data on the quality of synthetic sample, as generated by off-the-shelf Large Language Models (LLMs). We have undertaken rigorous side-by-side testing, comparing such a synthetic sample with real human responses, under a number of conditions.
Experiment 1: we asked GPT-4 to answer a ‘Likert’ question (responses on a scale of 1-5) and compared the responses to quantitative responses from a survey.
Experiment 2: we asked GPT-4 to generate verbatim responses to natural language questions and compared the results to real panellists’ responses.
We used survey data from around 5,000 respondents answering questions about a luxury product (identity disguised for confidentiality) and their attitudes toward technology. For each experiment, we used demographic markers from our human sample such as geographic location, age, ethnicity, income, education etc. as part of our ’prompt conditioning’ for GPT-4 to ensure that its responses would be comparable to the survey responses from that respondent profile. In effect, therefore, we created a ‘synthetic sample’ with identical demographic characteristics to our human sample.
What did we find?
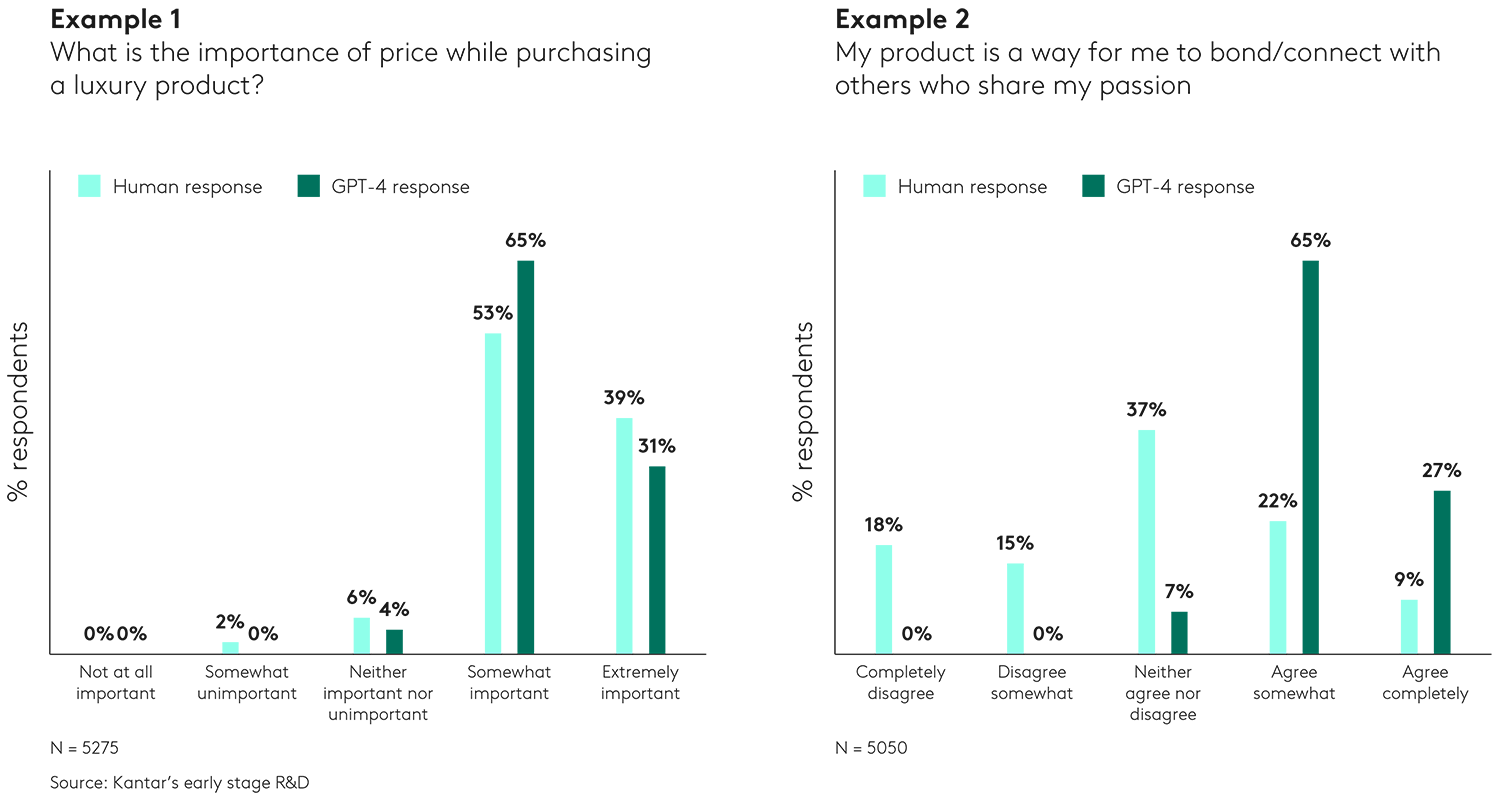
First, GPT-4 seems to be overly positive in responses compared to our human survey respondents. On the more practical question about the price of this product, GPT-4’s responses are aligned more closely to human responses. But on the questions that require a little more thought (emotion connected to using the product, for example), there is much greater deviation.
GPT-4 appears to have a strong positive bias
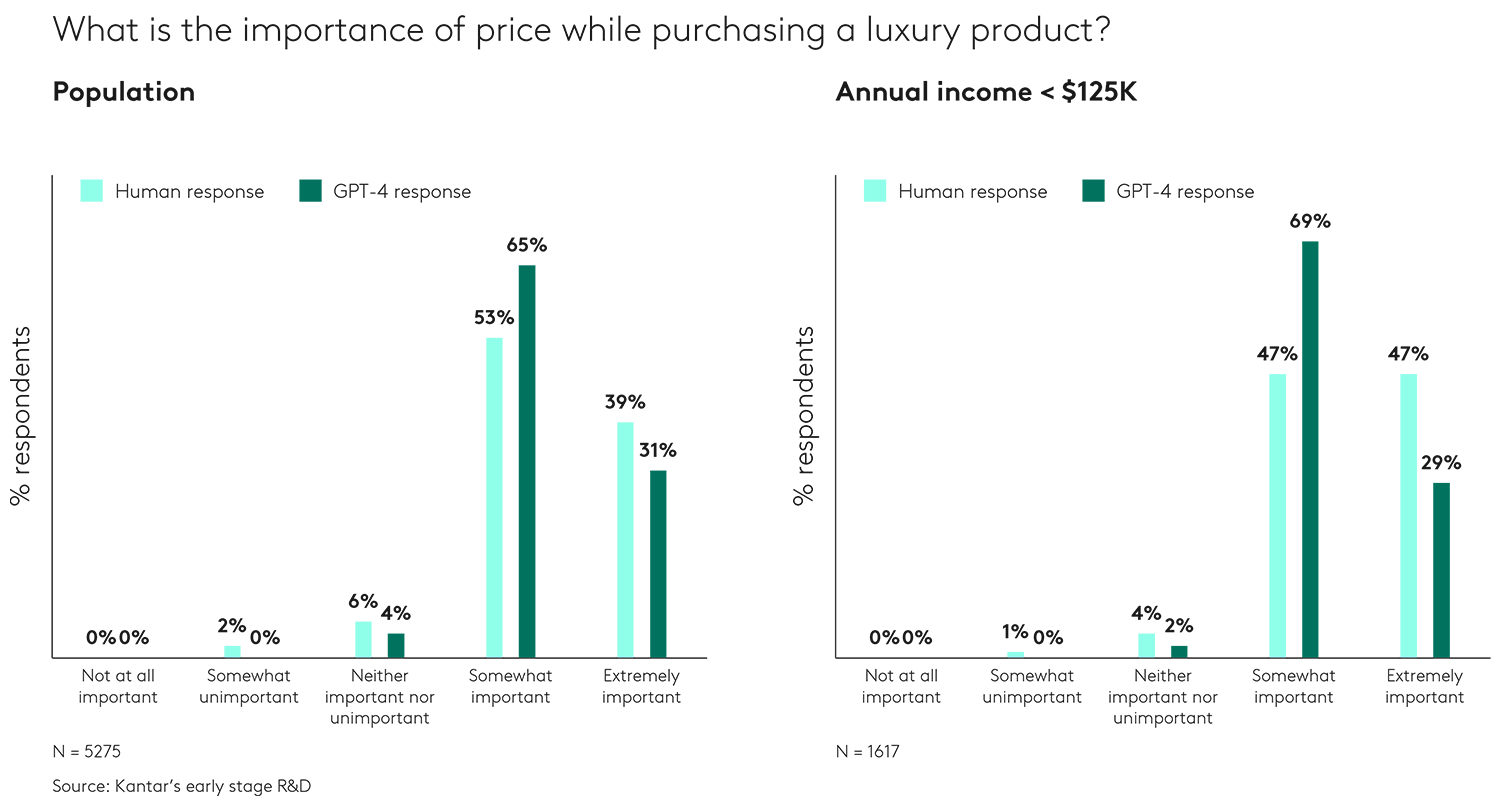
Second, GPT-4 also doesn’t deal with the nuance of data cuts into sub-groups very effectively. If we look at the distribution of answers about product pricing among the whole population, we see that GPT-4 is more positive on ‘somewhat important’ and less positive on ‘extremely important’. But if we look at the sub-group of those with an annual income of less than $125k, we see that GPT-4 is significantly overestimating the ‘somewhat important’ group and under-estimating the ‘extremely important’ group – so this human group considers that price is very important.
Sub-group analysis is an important one for marketers and currently synthetic sample is not sensitive enough for this task and shouldn’t be relied on.
GPT-4 doesn’t appear to capture sub-group trends
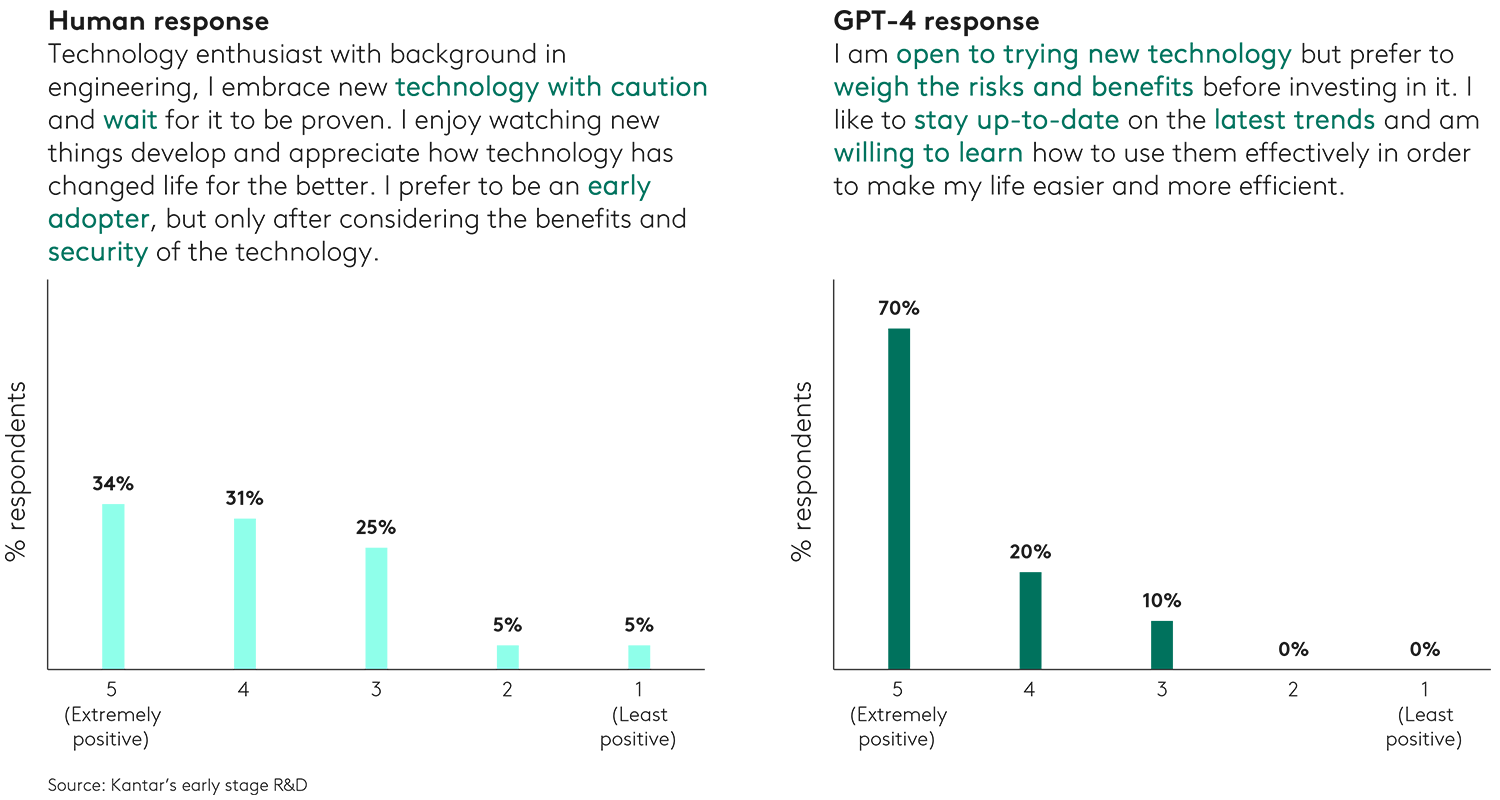
Third, for qualitative responses, we compare a typical human response to a question with a GPT-4 response, based on a 65+ Caucasian married male, living in the US. We asked about their overall attitude toward technology. On the face of it, their ‘verbatim’ responses seem fairly similar and not wildly out of line. However, when we repeat this experiment 50 times to get more variety, with a human expert manually coding each response on a 5-point scale, we see GPT-4’s response veers towards the stereotypical and lacked variance or nuance.
GPT-4 repeated responses steer massively positive relative to the 50 human responses.
Attitude to technology (qualitative): 65+ Caucasian married male, US
So is synthetic sample worth it?
These are early experiments. And importantly, these experiments are with off-the-shelf LLMs. Our conclusion is that right now, synthetic sample, as generated by these pre-trained LLMs has biases, lacks variation and nuance in both qual and quant analysis. On its own, as it stands, it’s just not good enough to use as a supplement for human sample.
And there are other issues to consider. For instance, it matters what subject is being discussed. General political orientation could be easy for a LLM but the trial of a new product is hard. And fundamentally, it will always be sensitive to its training data – something entirely new that is not part of its training will be off-limits. And the nature of questioning matters – a highly ’specific’ question that might require proprietary data or modelling (e.g., volume or revenue for a particular product in response to a price change) might elicit a poor-quality response, while a response to a general attitude or broad trend might be more acceptable.
One way to get the benefit of LLMs without asking them to answer arbitrary questions is to collect a training sample that is detailed, proprietary and specific to the topic of interest, use it to tweak the LLM and then use it on all questions relating to that topic. Obviously, this LLM will need to be periodically updated as new data related to the topic becomes available. This is an example of “fine-tuning” an LLM on use-case specific data, which we estimate will become more common in future.
Currently the hype is high and synthetic sample’s capabilities from off-the-shelf LLMs are far from meeting the quality of data required for market research. The foundation of market research and trustworthy decision-making is robust, high-quality data. Which is why Kantar’s Profiles Division invests in delivering the right balance between machine and human collaboration to deliver the biggest global source of compliant panel data. This means complementing our programmatic network of 170m+ human panellists in 100+ markets with Qubed, our industry-leading anti-fraud technology built off 3 deep neural networks, and empathetic survey design, to ensure we are creating communities of real, engaged panellists that deliver the highest quality, most meaningful data.
Whether you want to create a highly targeted product, elevate your brand, or better understand your customers, talking to real people, who are who they say they are, is the ultimate starting point. Ideas executed without real consumer-based insights are at higher risk of failing. So, for now, synthetic sampling doesn’t meet the brief.
But it’s likely that blended models (human supplemented by synthetic sample) will become more common as LLMs get even more powerful - especially as models are finetuned on proprietary datasets. And in fact, at Kantar, we can create our own synthetic datasets by going across various proprietary datasets that measure attitudes, demographics, behaviours, and media usage. So watch this space.
Get in touch for more information on the experimentation we are doing in the use of LLMs in market research.
