



We are hearing from brands who want to understand the basics and limitations of synthetic data. Meanwhile, Forbes predicts that synthetic data could become a $2.34 billion industry by 2030.
Synthetic data means different things to different people – and not all synthetic data is created equal. But what all synthetic methodologies have in common is that they don't create new humans – they create or infer data outcomes that might mirror the opinion or behaviours of real people.
Why does synthetic data matter for brands?
We know that Brands grow by being meaningfully different to more people. This is where synthetic data can help. Marketers can use synthetic data capabilities to understand more people, to make informed decisions and to explore new scenarios with confidence. Synthetic data can help brands win the micro-battles to predispose more people, be more present and find new space in a fragmented, personalised world.
Here are the most common use cases that we see:
• Boosting: using a model to create greater statistical power for subgroups. For example, if a survey has limited data from a particular demographic, can we synthetically generate more to represent that group more accurately?
• Imputation: the process of filling in gaps in a dataset using a model, often using external information. For example, can we track more brands without sacrificing questionnaire length and quality to benchmark within a wider context.
• Digital twins: leveraging historical and fresh information to extend and predict future behaviours and scenarios by creating a virtual model of a system or process that’s continuously updated with real-time data. For example, in market research, digital twins (also sometimes called ‘persona bots’) can use past survey responses to predict how a consumer might react to new products or trends.
Myths and realities
There are still a lot of misconceptions about what synthetic data can and can’t deliver.
Myth one: Synthetic data does not need human data for training
To be fit for decision making, synthetic modelling needs to reflect real-world complexities by not only learning from the past - time series data - but also leveraging the present – through fresh sample. This helps to ensure relevancy and currency.
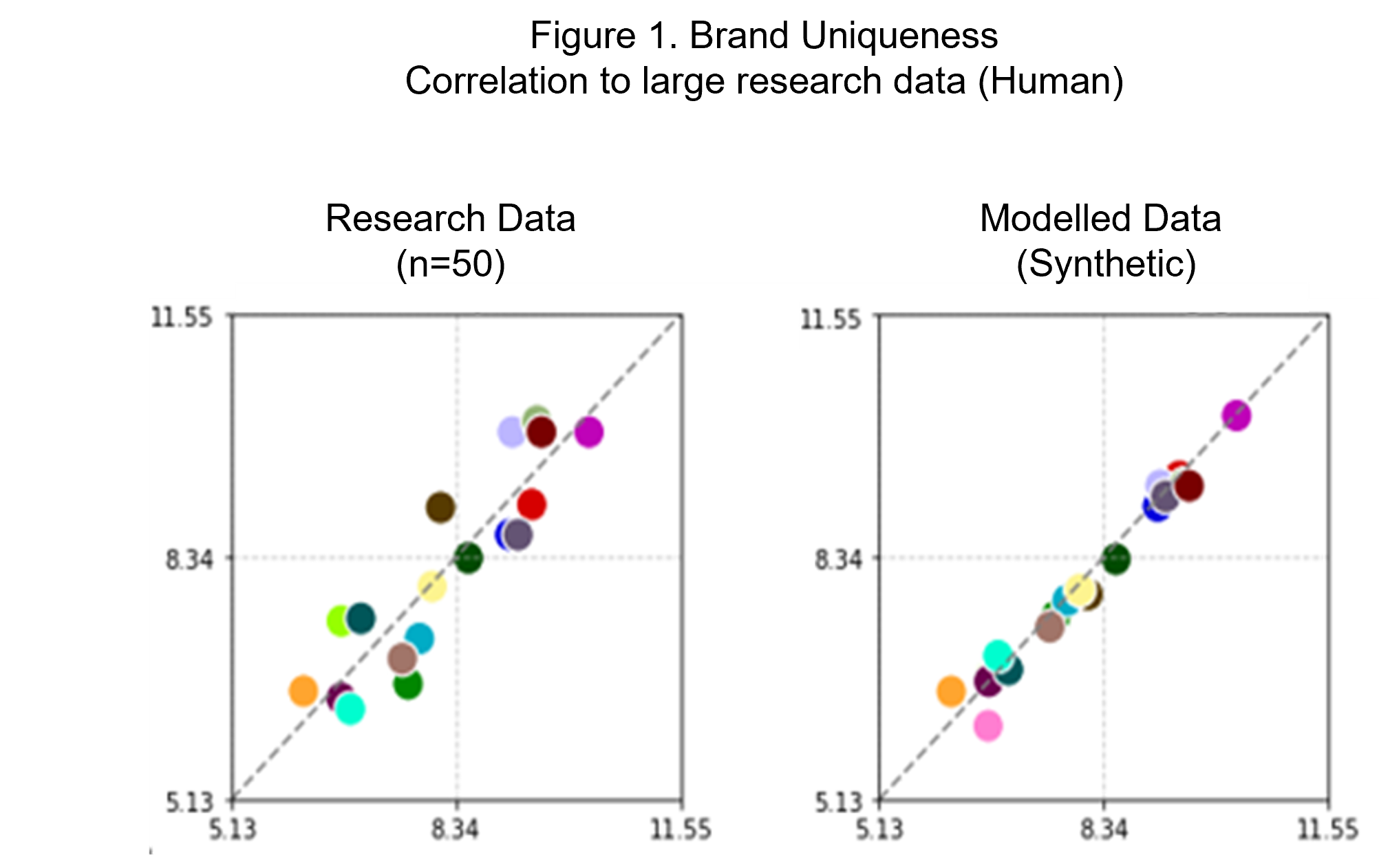
The Figure 1 below, shows brand uniqueness results for twenty one different brands. Synthetic data, when modelled on a fraud-free, fully permissioned human dataset, boosts accuracy and closely reflects larger human sample datasets.
Myth two: Synthetic data can answer any question autonomously
Digital twins use historical information to extend beyond previous survey questions into new similar categories, behaviours and topics. These questions need to be relevant to the training dataset, or the ‘knowledge’ of the persona, to help us predict responses. A digital twin trained on people’s food habits may be accurate in assessing a menu item concept, but that will likely not extrapolate to someone’s banking preferences.
Myth three: Switching to synthetic is easy
The real power of synthetic data comes when it is applied systematically to large-scale programmes such as brand tracking. And this isn’t easy; you need a structured process of boosting and adjusting many hard-to-reach audiences, monthly, weekly and even daily.
Relying solely on data from platform providers involves the cumbersome task of uploading and downloading files for thousands of audiences across numerous brands. This data needs to be integrated, weighted, analysed and monitored for consistency and quality. For example, how is the overall sample affected if you increase the representation of specific groups?
If businesses use an application programme interface (API), advanced analytics are needed to equip the models with guardrails and validations. Technology is needed to automate processes and infrastructure, and to host and process the large-scale calculations.
So it's not simple: there are many details that are critical to success.
From validation to transformation: Kantar's synthetic data journey
We’ve carried out extensive validations and are already applying synthetic data methodologies at enterprise level for Brand Guidance programmes, conducting cutting-edge experimentation on large human datasets of over seven million people.
We have invested heavily in a state-of-the-art data ecosystem for long-term, sustainable transformation. It’s because we believe in innovation that’s trustworthy – always trained on sample that is fresh, fraud-free, compliant, ethical and scalable, to enable better decisions.
To move beyond the hype in their transformation journey, brands can ensure that their data accurately represents the consumer voice. Having a partner who can implement cutting edge innovation and ensure reliable data quality is crucial to effectively understand and meet consumer needs.
When you read about how easy synthetic data is, ask yourself these questions:
o How reliable are the datasets used to train the synthetic model?
o How relevant are the training datasets to the project or questions you have?
o How often is the training data refreshed?
o How accurate is your model? Has it been validated?
o What guardrails do you have against your model generating irrelevant data?
o Are you folding in synthetic data with human data, and are you taking into account the benefits and risks of synthetic data in your downstream applications?
Learn more about the opportunities and challenges in synthetic data here.
Want to learn more? Get in touch with Kantar HERE